mirror of
https://github.com/MacRimi/ProxMenux.git
synced 2026-06-16 14:58:28 +00:00
Update CHANGELOG.md
This commit is contained in:
402
CHANGELOG.md
402
CHANGELOG.md
@@ -1,3 +1,405 @@
|
||||
|
||||
## 2026-04-20
|
||||
|
||||
### New version ProxMenux v1.2.1 — *SR-IOV Awareness & GPU Passthrough Hardening*
|
||||
|
||||
Targeted release on top of **v1.2.0** addressing three community-reported areas that needed fixing before the next stable cycle: full SR-IOV awareness across the GPU/PCI subsystem, robust handling of GPU + audio companions during passthrough attach and detach (Intel iGPU with chipset audio, discrete cards with HDMI audio, mixed-GPU VMs), and compatibility fixes for the AI notification providers (OpenAI-compatible custom endpoints such as LiteLLM/MLX/LM Studio, OpenAI reasoning models, and Gemini 2.5+/3.x thinking models). Also bundles quality-of-life fixes in the NVIDIA installer, the disk health monitor, and the LXC lifecycle helpers used by the passthrough wizards.
|
||||
|
||||
---
|
||||
|
||||
## 🎛️ SR-IOV Awareness Across the GPU Subsystem
|
||||
|
||||
Intel `i915-sriov-dkms` and AMD MxGPU split a GPU's Physical Function (PF) into Virtual Functions (VFs) that can be assigned independently to LXCs and VMs. Previously ProxMenux had zero SR-IOV awareness: it treated VFs and PFs identically, which could rewrite `vfio.conf` with the PF's vendor:device ID, collapse the VF tree on the next boot, and leave users unable to start their guests. Every path that could disrupt an active VF tree has been audited and hardened.
|
||||
|
||||
### Detection helpers
|
||||
- New `_pci_is_vf`, `_pci_has_active_vfs`, `_pci_sriov_role`, `_pci_sriov_filter_array` in `scripts/global/pci_passthrough_helpers.sh`
|
||||
- HTTP/JSON equivalents in the Flask GPU route — the Monitor UI reads VF/PF state directly from sysfs (`physfn`, `sriov_totalvfs`, `sriov_numvfs`, `virtfn*`)
|
||||
|
||||
### Pre-start hook (`gpu_hook_guard_helpers.sh`)
|
||||
The VM pre-start guard now recognises Virtual Functions. Both the slot-only syntax branch (which used to iterate every function of the slot and demand `vfio-pci` everywhere) and the full-BDF branch skip VFs, so Proxmox can perform its per-VF vfio-pci rebind as usual. The false "GPU passthrough device is not ready" block on SR-IOV VMs is gone.
|
||||
|
||||
### Mode-switch scripts refuse SR-IOV operations
|
||||
`switch_gpu_mode.sh`, `switch_gpu_mode_direct.sh`, `add_gpu_vm.sh`, `add_gpu_lxc.sh`, `vm_creator.sh`, `synology.sh`, `zimaos.sh` and `add_controller_nvme_vm.sh` all reject VFs and PFs with active VFs before touching host configuration. A clear "SR-IOV Configuration Detected" dialog explains the situation. For wizards invoked mid-flow (VM creators) the message is delivered through `whiptail` so it interrupts cleanly, followed by a per-device `msg_warn` line for the log trail.
|
||||
|
||||
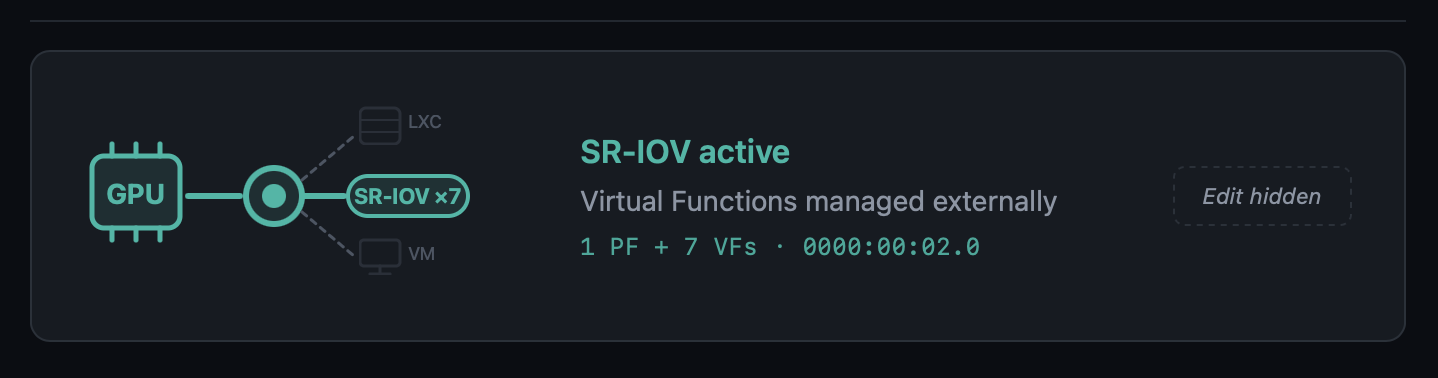
### New "SR-IOV active" state in the Monitor UI
|
||||
The GPU card in the Hardware page gains a third visual state with a dedicated teal colour, an in-line `SR-IOV ×N` pill (or `SR-IOV VF` for a Virtual Function), and dashed/faded LXC and VM branches. The Edit button is hidden because the state is hardware-managed.
|
||||
|
||||
|
||||
|
||||
### Modal dashboard for SR-IOV GPUs
|
||||
Opening the modal for a Physical Function with active VFs now shows:
|
||||
- Aggregate-metrics banner ("Metrics below reflect the Physical Function, aggregate across N VFs")
|
||||
- Normal GPU real-time telemetry for the PF
|
||||
- A **Virtual Functions** table, one row per VF, with the current driver (`i915`, `vfio-pci`, unbound) and the specific VM or LXC that consumes it, including running/stopped state — consumers are discovered by cross-referencing `hostpci` entries and `/dev/dri/renderDN` mount lines against the VF's BDF and DRM render node
|
||||
|
||||
Opening the modal for a Virtual Function shows its parent PF (clickable to navigate back to the PF's modal), current driver, and consumer.
|
||||
|
||||
### VM Conflict Policy popup no longer fires for SR-IOV VFs
|
||||
The regex in `detect_affected_vms_for_selected` matched the slot (`00:02`) against VMs that had a VF (`00:02.1`) assigned, producing a confusing "Keep GPU in VM config" dialog. With the SR-IOV gate upstream, the flow never reaches that code path for SR-IOV slots.
|
||||
|
||||
---
|
||||
|
||||
## 🔊 GPU + Audio Passthrough — Full Lifecycle Hardening
|
||||
|
||||
A round of fixes around how GPU passthrough handles its audio companion device. Previously, only the `.1` sibling of a discrete GPU was picked up automatically; Intel iGPU passthrough to a VM — where the audio lives separately on the chipset at `00:1f.3` and not at `00:02.1` — was silently skipped. On detach, the old `sed` that wiped hostpci lines by slot substring could also remove an unrelated GPU whose BDF happened to contain the search slot as a substring (e.g. slot `00:02` matching inside `0000:02:00.0`). Both paths are now robust.
|
||||
|
||||
### iGPU audio-companion checklist on attach
|
||||
`add_gpu_vm.sh::detect_optional_gpu_audio` keeps the auto-include fast path for the classic `.1` sibling (discrete NVIDIA / AMD with HDMI audio on the card). When no `.1` audio exists, the script now:
|
||||
- Scans sysfs for every PCI audio controller on the host
|
||||
- Skips anything already covered by the GPU's IOMMU group
|
||||
- Asks the user via a `_pmx_checklist` (`dialog` in standalone mode, `whiptail` in wizard mode called from `vm_creator`/`synology`/`zimaos`) which audio controllers to pass through alongside the GPU
|
||||
- Displays each entry with its current host driver (`snd_hda_intel`, `snd_hda_codec_*`, etc.) so the decision is informed
|
||||
- Defaults to **none** — the user actively opts in
|
||||
|
||||
### Orphan audio cascade on detach
|
||||
When the user picks "Remove GPU from VM config" during a mode switch, the scripts now follow up with a targeted cleanup:
|
||||
- `switch_gpu_mode.sh`, `switch_gpu_mode_direct.sh` and `add_gpu_vm.sh::cleanup_vm_config` (source-VM cleanup on the "move GPU" flow) all call the shared helper `_vm_list_orphan_audio_hostpci`
|
||||
- The helper uses a two-pass scan of the VM config: pass 1 records slot bases of display/3D hostpci entries; pass 2 classifies audio entries and **skips any audio whose slot still has a display sibling in the same VM** — protecting the HDMI audio of other dGPUs left in the VM
|
||||
- Previously the bare substring match would have flagged NVIDIA's `02:00.1` as orphan when detaching an Intel iGPU at `00:02.0`
|
||||
- The interactive switch flow confirms removals with a `dialog` checklist (default ON). The web variant auto-removes without prompting — the runner has no good way to render a checklist — and logs every BDF it touched
|
||||
|
||||
### vfio.conf cascade extension
|
||||
For each audio removed by the cascade, the switch-mode scripts now check whether its BDF is still referenced by any other VM via `_pci_bdf_in_any_vm`. If nothing else uses it, the `vendor:device` is appended to `SELECTED_IOMMU_IDS` before the `/etc/modprobe.d/vfio.conf` update runs. That closes the loop for the Intel iGPU case: `8086:51c8` (PCH HD Audio) is now pulled from `vfio.conf` alongside `8086:46a3` (iGPU) when both leave VM mode and no other VM references them. If another VM still uses the audio, the ID is deliberately kept — no breaking side effects on other VMs. `add_gpu_vm.sh` does NOT extend the cleanup in the *move* flow, because the GPU is still in use elsewhere and its IDs must remain.
|
||||
|
||||
### Precise hostpci removal regex
|
||||
Every inline `sed` used to detach a GPU from a VM config previously matched the slot as a free substring:
|
||||
```
|
||||
/^hostpci[0-9]+:.*${slot}/d
|
||||
```
|
||||
For `slot=00:02` that pattern matches the substring inside `0000:02:00.0` (an unrelated NVIDIA dGPU at slot `02:00`) and would wipe both cards. The fix anchors the match to the real BDF shape:
|
||||
```
|
||||
/^hostpci[0-9]+:[[:space:]]*(0000:)?${slot}\.[0-7]([,[:space:]]|$)/d
|
||||
```
|
||||
Applied in `switch_gpu_mode.sh`, `switch_gpu_mode_direct.sh` and `add_gpu_vm.sh::cleanup_vm_config`. The awk-based helper in `vm_storage_helpers.sh::_remove_pci_slot_from_vm_config` (used by the NVMe wizards) already used the correct pattern and did not need changes.
|
||||
|
||||
---
|
||||
|
||||
## 🤖 AI Provider Compatibility — OpenAI-Compatible, Reasoning & Thinking Models
|
||||
|
||||
Three coordinated fixes that unblock model categories previously rejected by the notification enhancement pipeline.
|
||||
|
||||
### OpenAI-compatible endpoints
|
||||
LiteLLM, MLX, LM Studio, vLLM, LocalAI, Ollama-proxy — the provider's `list_models()` used to require `"gpt"` in every model name, so local setups serving `mlx-community/...`, `Qwen3-...`, `mistralai/...` saw an empty model list. When a Custom Base URL is set, the `"gpt"` substring check is now skipped and `EXCLUDED_PATTERNS` (embeddings, whisper, tts, dall-e) is the only filter. The Flask route layer also stops intersecting the result against `verified_ai_models.json` for custom endpoints — the verified list only describes OpenAI's official model IDs and was erasing every local model the user actually served.
|
||||
|
||||
### OpenAI reasoning models
|
||||
`o1`, `o3`, `o3-mini`, `o4-mini`, `gpt-5`, `gpt-5-mini`, `gpt-5.1`, `gpt-5.2-pro`, `gpt-5.4-nano`, etc. (excluding the `*-chat-latest` variants) use a stricter API contract: `max_completion_tokens` instead of `max_tokens`, no `temperature`. Sending the classic chat parameters produced HTTP 400 Bad Request for every one of them. A detector in `openai_provider.py` now branches the payload accordingly and sets `reasoning_effort: "minimal"` — by default these models spend their output budget on internal reasoning and return an empty reply for the short notification-translation request.
|
||||
|
||||
### Gemini 2.5+ / 3.x thinking models
|
||||
`gemini-2.5-flash`, `2.5-pro`, `gemini-3-pro-preview`, `gemini-3.1-pro-preview`, etc. have internal "thinking" enabled by default. With the small token budget used for notification enrichment (≤250 tokens), the thinking budget consumed the entire allowance and the model returned empty output with `finishReason: MAX_TOKENS`. `gemini_provider.py` now sets `thinkingConfig.thinkingBudget: 0` for non-`lite` variants of 2.5+ and 3.x, so the available tokens go to the user-visible response. Lite variants (no thinking enabled) are untouched.
|
||||
|
||||
---
|
||||
|
||||
## 📋 Verified AI Models Refresh
|
||||
|
||||
`AppImage/config/verified_ai_models.json` refreshed for the providers re-tested against live APIs. The new private maintenance tool (kept out of the AppImage) re-runs a standardised translate+explain test against every model each provider advertises, classifies pass / warn / fail, and prints a ready-to-paste JSON snippet. Re-run before each ProxMenux release to keep the list current.
|
||||
|
||||
| Provider | New recommended | Notes |
|
||||
|----------|-----------------|-------|
|
||||
| **OpenAI** | `gpt-4.1-nano` | `gpt-4.1-nano`, `gpt-4.1-mini`, `gpt-4o-mini`, `gpt-4.1`, `gpt-4o`, `gpt-5-chat-latest`, plus `gpt-5.4-nano` / `gpt-5.4-mini` from 2026-03. Dated snapshots and legacy models excluded. Reasoning models supported by code but not listed by default — slower / costlier without improving notification quality |
|
||||
| **Gemini** | `gemini-2.5-flash-lite` | `gemini-2.5-flash-lite`, `gemini-2.5-flash` (works now), `gemini-3-flash-preview`. `latest` aliases intentionally omitted — resolved to different models across runs and produced timeouts in some regions. Pro variants reject `thinkingBudget=0` and are overkill for notification translation |
|
||||
| Groq / Anthropic / OpenRouter | *unchanged* | Marked with a `_note` — will be re-verified as soon as keys are available |
|
||||
|
||||
---
|
||||
|
||||
## 🩺 Disk Health Monitor — Observation Persistence in the Journal Watcher
|
||||
|
||||
A latent bug in `notification_events.py::_check_disk_io` meant real-time kernel I/O errors caught by the journal watcher were surfaced as notifications but never written to the permanent per-disk observations table. In practice the parallel periodic dmesg scan usually recorded the observation shortly after, but under timing edge cases (stale dmesg window, service restart right after the error, buffer rotation) the observation could go missing.
|
||||
|
||||
The journal watcher now records the observation before the 24h notification cooldown gate, using the same family-based signature classification (`io_<disk>_ata_connection_error`, `io_<disk>_block_io_error`, `io_<disk>_ata_failed_command`) as the periodic scan. Both paths now deduplicate into the same row via the UPSERT in `record_disk_observation`, so occurrence counts are accurate regardless of which detector fired first.
|
||||
|
||||
---
|
||||
|
||||
## 🔧 NVIDIA Installer Polish
|
||||
|
||||
### `lsmod` race condition silenced
|
||||
During reinstall, the module-unload verification in `unload_nvidia_modules` produced spurious `lsmod: ERROR: could not open '/sys/module/nvidia_uvm/holders'` errors because `lsmod` reads `/proc/modules` and then opens each module's `holders/` directory, which disappears transiently while the module is being removed. The check now reads `/proc/modules` directly and inserts short sleeps to let the kernel finalise the unload before re-verifying. Applied in the same spirit to the four other `lsmod` call sites in the script.
|
||||
|
||||
### Dialog → whiptail in the LXC update flow
|
||||
The "Insufficient Disk Space" message in `update_lxc_nvidia` and the "Update NVIDIA in LXC Containers" confirmation now use `whiptail`-style dialogs consistent with the rest of the in-flow messaging, avoiding the visual break that `dialog --msgbox` caused when rendered mid-sequence in the container-update phase.
|
||||
|
||||
---
|
||||
|
||||
## 🧵 LXC Lifecycle Helper — Timeout-Safe Stop
|
||||
|
||||
A plain `pct stop` can hang indefinitely when the container has a stale lock from a previous aborted operation, when processes inside (Plex, Jellyfin, databases) ignore TERM and fall into uninterruptible-sleep while the GPU they were using is yanked out, or when `pct shutdown --timeout` is not enforced by pct itself. Field reports of 5+ min waits during GPU mode switches made this a real UX hazard.
|
||||
|
||||
New shared helper `_pmx_stop_lxc <ctid> [log_file]` in `pci_passthrough_helpers.sh`:
|
||||
1. Returns 0 immediately if the container is not running
|
||||
2. Best-effort `pct unlock` (silent on failure) — most containers aren't actually locked; we only care about the cases where they are
|
||||
3. `pct shutdown --forceStop 1 --timeout 30` wrapped in an external `timeout 45` so we never wait longer than that for the graceful phase, even if pct stalls on backend I/O
|
||||
4. Verifies actual status via `pct status` — pct can return non-zero while the container is in fact stopped
|
||||
5. If still running, `pct stop` wrapped in `timeout 60`. Verify again
|
||||
6. Returns 1 only if the container is truly stuck after ~107 s total — the wizard moves on instead of hanging
|
||||
|
||||
Wired into the three GPU-mode paths that stop LXCs during a switch: `switch_gpu_mode.sh`, `switch_gpu_mode_direct.sh`, and `add_gpu_vm.sh::cleanup_lxc_configs`.
|
||||
|
||||
---
|
||||
|
||||
## ⚙️ `add_gpu_vm.sh` Reboot Prompt Stability
|
||||
|
||||
The final "Reboot Required" prompt of the GPU-to-VM assignment wizard was triggering spurious reboots in certain menu-chain invocations (`menu` → `main_menu` → `hw_grafics_menu` → `add_gpu_vm`). With the `_pmx_yesno` helper it sometimes returned exit 0 without the user having actually confirmed, calling `reboot` immediately. With a bare `read` in its place the process would get SIGTTIN-suspended when the menu chain detached the script from the terminal's foreground process group, leaving `[N]+ Stopped menu` on the parent shell with no chance to answer.
|
||||
|
||||
The prompt now uses `whiptail --yesno` invoked directly (the pattern verified to work reliably in that menu chain) and inserts a `Press Enter to continue ... read -r` pause between the "Yes" answer and the actual `reboot` call — so an accidental Enter on the confirm button cannot trigger an immediate reboot without a visible confirmation step first.
|
||||
|
||||
---
|
||||
|
||||
### 🙏 Thanks
|
||||
|
||||
Thank you to the users who reported the SR-IOV, LiteLLM/MLX and GPU + audio cases — these improvements exist because of detailed, reproducible reports. Feel free to keep reporting issues or suggesting improvements 🙌.
|
||||
|
||||
---
|
||||
|
||||
|
||||
## 2026-04-17
|
||||
|
||||
### New version ProxMenux v1.2.0 — *AI-Enhanced Monitoring*
|
||||
|
||||
|
||||

|
||||
|
||||
This release is the culmination of the v1.1.9.1 → v1.1.9.6 beta cycle and introduces the biggest evolution of **ProxMenux Monitor** to date: AI-enhanced notifications, a redesigned multi-channel notification system, a fully reworked hardware and storage experience, and broad performance improvements across the monitoring stack. It also consolidates all recent work on the Storage, Hardware and GPU/TPU scripts.
|
||||
|
||||
---
|
||||
|
||||
## 🤖 ProxMenux Monitor — AI-Enhanced Notifications
|
||||
|
||||
Notifications can now be enhanced using AI to generate clear, contextual messages instead of raw technical output.
|
||||
|
||||
Example — instead of `backup completed exitcode=0 size=2.3GB`, AI produces: *"The web server backup completed successfully. Size: 2.3GB"*.
|
||||
|
||||
### What AI does
|
||||
- Transforms technical notifications into readable messages
|
||||
- Translates to your preferred language
|
||||
- Lets you choose detail level: minimal, standard, or detailed
|
||||
- Works with Telegram, Discord, Email, Pushover, and Webhooks
|
||||
|
||||
### What AI does NOT do
|
||||
- It is **not** a chatbot or assistant
|
||||
- It does **not** analyze your system or make decisions
|
||||
- It does **not** have access to data beyond the notification being processed
|
||||
- It does **not** execute commands or modify the server
|
||||
- It does **not** store history or learn from your data
|
||||
|
||||
### Multi-Provider Support
|
||||
Choose between 6 AI providers, each with its own API key stored independently:
|
||||
- **Groq** — fast inference, generous free tier
|
||||
- **Google Gemini** — excellent quality/price ratio, free tier available
|
||||
- **OpenAI** — industry standard
|
||||
- **Anthropic Claude** — excellent for writing and translation
|
||||
- **OpenRouter** — 300+ models with a single API key
|
||||
- **Ollama** — 100% local execution, no internet required
|
||||
|
||||
### Verified AI Models
|
||||
A curated list of models (`verified_ai_models.json`) tested specifically for notification enhancement.
|
||||
|
||||
- **Hybrid verification**: the system fetches provider-side models and filters to only show those tested to work correctly
|
||||
- **Per-Provider Model Memory**: selected model is saved per provider, so switching providers preserves each choice
|
||||
- **Daily verification**: background task checks model availability and auto-migrates to a verified alternative if the current model disappears
|
||||
- **Incompatible models excluded**: Whisper, TTS, image/video, embeddings, guard models, etc. are filtered out per provider
|
||||
|
||||
| Provider | Recommended | Also Verified |
|
||||
|----------|-------------|---------------|
|
||||
| Gemini | gemini-2.5-flash-lite | gemini-flash-lite-latest |
|
||||
| OpenAI | gpt-4o-mini | gpt-4.1-mini |
|
||||
| Groq | llama-3.3-70b-versatile | llama-3.1-70b-versatile, llama-3.1-8b-instant, llama3-70b-8192, llama3-8b-8192, mixtral-8x7b-32768, gemma2-9b-it |
|
||||
| Anthropic | claude-3-5-haiku-latest | claude-3-5-sonnet-latest, claude-3-opus-latest |
|
||||
| OpenRouter | meta-llama/llama-3.3-70b-instruct | meta-llama/llama-3.1-70b-instruct, anthropic/claude-3.5-haiku, google/gemini-flash-2.5-flash-lite, openai/gpt-4o-mini, mistralai/mixtral-8x7b-instruct |
|
||||
| Ollama | (all local models) | No filtering — shows all installed models |
|
||||
|
||||
### Custom AI Prompts
|
||||
Advanced users can define their own prompt for full control over formatting and translation.
|
||||
|
||||
- **Prompt Mode selector** — Default Prompt or Custom Prompt
|
||||
- **Export / Import** — save and share custom prompts across installations
|
||||
- **Example Template** — starting point to build your own prompt
|
||||
- **Community Prompts** — direct link to GitHub Discussions to share templates
|
||||
- Language selector is hidden in Custom Prompt mode (you define the output language in the prompt itself)
|
||||
|
||||
### Enriched Context
|
||||
- System **uptime** is included only for error/warning events (not informational ones) — helps distinguish startup vs runtime errors
|
||||
- **Event frequency** tracking — indicates recurring vs one-time issues
|
||||
- **SMART disk health** data is passed for disk-related errors
|
||||
- **Known Proxmox errors** database improves diagnosis accuracy
|
||||
- Clearer prompt instructions to prevent AI hallucinations
|
||||
|
||||
---
|
||||
|
||||
## 📨 Notification System Redesign
|
||||
|
||||
- **Multi-Channel Architecture** — Telegram, Discord, Pushover, Email, and Webhook channels running simultaneously
|
||||
- **Per-Event Configuration** — enable/disable specific event types per channel
|
||||
- **Channel Overrides** — customize notification behaviour per channel
|
||||
- **Secure Webhook Endpoint** — external systems can send authenticated notifications
|
||||
- **Encrypted Storage** — API keys and sensitive data stored encrypted
|
||||
- **Queue-Based Processing** — background worker with automatic retry for failed notifications
|
||||
- **SQLite-Based Config Storage** — replaces file-based config for reliability
|
||||
|
||||
### Telegram Topics Support
|
||||
Send notifications to a specific topic inside groups with Topics enabled.
|
||||
- New **Topic ID** field on the Telegram channel
|
||||
- Automatic detection of topic-enabled groups
|
||||
- Fully backwards compatible
|
||||
|
||||
### ProxMenux Update Notifications
|
||||
The Monitor now detects when a new ProxMenux version is released.
|
||||
- **Dual-channel** — monitors both stable (`version.txt`) and beta (`beta_version.txt`)
|
||||
- **GitHub integration** — compares local vs remote versions
|
||||
- **Dashboard Update Indicator** — the ProxMenux logo changes to an update variant when a new version is detected (non-intrusive, no popups)
|
||||
- **Persistent state** — status stored in `config.json`, reset by update scripts
|
||||
- Single toggle in Settings controls both channels (enabled by default)
|
||||
|
||||
---
|
||||
|
||||
## 🖥️ Hardware Panel — Expanded Detection
|
||||
|
||||
The Hardware page has been significantly expanded, with better detection and richer per-device detail.
|
||||
|
||||
- **SCSI / SAS / RAID Controllers** — model, driver and PCI slot shown in the storage controllers section
|
||||
- **PCIe Link Speed Detection** — NVMe drives show current link speed (PCIe generation and lane width), making it easy to spot drives underperforming due to limited slot bandwidth
|
||||
- **Enhanced Disk Detail Modal** — NVMe, SATA, SAS, and USB drives now expose their specific fields (PCIe link info, SAS version/speed, interface type) instead of a generic view
|
||||
- **Smarter Disk Type Recognition** — uniform labelling for NVMe SSDs, SATA SSDs, HDDs and removable disks
|
||||
- **Hardware Info Caching** (`lspci`, `lspci -vmm`) — 5 min cache avoids repeated scans for data that doesn't change
|
||||
|
||||
---
|
||||
|
||||
## 💽 Storage Overview — Health, Observations, Exclusions
|
||||
|
||||
The Storage Overview has been reworked around real-time state and user-controlled tracking.
|
||||
|
||||
### Disk Health Status Alignment
|
||||
- Badges now reflect the **current** SMART state reported by Proxmox, not a historical worst value
|
||||
- **Observations preserved** — historical findings remain accessible via the "X obs." badge
|
||||
- **Automatic recovery** — when SMART reports healthy again, the disk immediately shows **Healthy**
|
||||
- Removed the old `worst_health` tracking that required manual clearing
|
||||
|
||||
### Disk Registry Improvements
|
||||
- **Smart serial lookup** — when a serial is unknown the system checks for an existing entry with a serial before inserting a new one
|
||||
- **No more duplicates** — prevents separate entries for the same disk appearing with/without a serial
|
||||
- **USB disk support** — handles USB drives that may appear under different device names between reboots
|
||||
|
||||
### Storage and Network Interface Exclusions
|
||||
- **Storage Exclusions** section — exclude drives from health monitoring and notifications
|
||||
- **Network Interface Exclusions** — new section for excluding interfaces (bridges `vmbr`, bonds, physical NICs, VLANs) from health and notifications; ideal for intentionally disabled interfaces that would otherwise generate false alerts
|
||||
- **Separate toggles** per item for Health monitoring and Notifications
|
||||
|
||||
### Disk Detection Robustness
|
||||
- **Power-On-Hours validation** — detects and corrects absurdly large values (billions of hours) on drives with non-standard SMART encoding
|
||||
- **Intelligent bit masking** — extracts the correct value from drives that pack extra info into high bytes
|
||||
- **Graceful fallback** — shows "N/A" instead of impossible numbers when data cannot be parsed
|
||||
|
||||
---
|
||||
|
||||
## 🧠 Health Monitor & Error Lifecycle
|
||||
|
||||
### Stale Error Cleanup
|
||||
Errors for resources that no longer exist are now resolved automatically.
|
||||
- **Deleted VMs / CTs** — related errors auto-resolve when the resource is removed
|
||||
- **Removed Disks** — errors for disconnected USB or hot-swap drives are cleaned up
|
||||
- **Cluster Changes** — cluster errors clear when a node leaves the cluster
|
||||
- **Log Patterns** — log-based errors auto-resolve after 48 hours without recurrence
|
||||
- **Security Updates** — update notifications auto-resolve after 7 days
|
||||
|
||||
### Database Migration System
|
||||
- **Automatic column detection** — missing columns are added on startup
|
||||
- **Schema compatibility** — works with both old and new column naming conventions
|
||||
- **Backwards compatible** — databases from older ProxMenux versions are supported
|
||||
- **Graceful migration** — no data loss during schema updates
|
||||
|
||||
---
|
||||
|
||||
## 🧩 VM / CT Detail Modal
|
||||
|
||||
The VM/CT detail modal has been completely redesigned for usability.
|
||||
|
||||
- **Tabbed Navigation** — *Overview* (general information, status, resource usage) and *Backups* (dedicated history)
|
||||
- **Visual Enhancements** — icons throughout, improved hierarchy and spacing, better VM vs CT distinction
|
||||
- **Mobile Responsiveness** — adapts correctly to mobile screens in both webapp and direct browser access, no more overflow on small devices
|
||||
- **Touch-Friendly Controls** — larger buttons and spacing
|
||||
|
||||
### Secure Gateway Modal
|
||||
- **Scrollable storage list** when many destinations are available
|
||||
- Mobile-adapted layout and improved visual hierarchy
|
||||
|
||||
### Terminal Connection
|
||||
- **Reconnection loop fix** that was affecting mobile devices
|
||||
- Improved WebSocket handling for mobile browsers
|
||||
- More graceful connection timeout recovery
|
||||
|
||||
### Fail2ban & Lynis Management
|
||||
- **Delete buttons** added in Settings for both tools
|
||||
- Clean removal of packages and configuration files
|
||||
- Confirmation dialog to prevent accidental deletion
|
||||
|
||||
---
|
||||
|
||||
## ⚡ Performance Optimizations
|
||||
|
||||
Major reduction in CPU usage and elimination of spikes on the Monitor.
|
||||
|
||||
### Staggered Polling Intervals
|
||||
Collectors now run on offset schedules to prevent simultaneous execution:
|
||||
|
||||
| Collector | Schedule |
|
||||
|-----------|----------|
|
||||
| CPU sampling | Every 30s at offset 0 |
|
||||
| Temperature sampling | Every 15s at offset 7s |
|
||||
| Latency pings | Every 60s at offset 25s |
|
||||
| Temperature record | Every 60s at offset 40s |
|
||||
| Health collector | Starts at 55s offset |
|
||||
| Notification polling | Health=10s, Updates=30s, ProxMenux=45s, AI=50s |
|
||||
|
||||
### Cached System Information
|
||||
Expensive commands now cached to reduce repeated execution:
|
||||
|
||||
| Command | Cache TTL | Impact |
|
||||
|---------|-----------|--------|
|
||||
| `pveversion` | 6 hours | Eliminates 23%+ CPU spikes from Perl execution |
|
||||
| `apt list --upgradable` | 6 hours | Reduces package manager queries |
|
||||
| `pvesh get /cluster/resources` | 30 seconds | 6 API calls per request reduced to 1 |
|
||||
| `sensors` | 10 seconds | Temperature readings cached between polls |
|
||||
| `smartctl` (SMART health) | 30 minutes | Disk health checks reduced from every 5 min |
|
||||
| `lspci` / `lspci -vmm` | 5 minutes | Hardware info cached (doesn't change) |
|
||||
| `journalctl --since 24h` | 1 hour | Login attempts count cached (92% reduction) |
|
||||
|
||||
### Increased journalctl Timeouts
|
||||
Prevents timeout cascades under system load:
|
||||
|
||||
| Query Type | Before | After |
|
||||
|------------|--------|-------|
|
||||
| Short-term (3-10 min) | 3s | 10s |
|
||||
| Medium-term (1 hour) | 5s | 15s |
|
||||
| Long-term (24 hours) | 5s | 20s |
|
||||
|
||||
### Reduced Polling Frequency
|
||||
- `TaskWatcher` interval raised from **2s → 5s** (60% fewer checks)
|
||||
|
||||
### GitHub Actions
|
||||
- All workflow actions upgraded to **v6** for Node.js 24 compatibility
|
||||
- Deprecation warnings eliminated in CI/CD
|
||||
|
||||
---
|
||||
|
||||
## 🧰 Scripts — Storage, Hardware and GPU/TPU Work
|
||||
|
||||
This release also consolidates significant work on the core ProxMenux scripts.
|
||||
|
||||
### Storage scripts
|
||||
- **SMART scheduled tests** and improved interactive SMART test workflow with clearer progress feedback
|
||||
- **Disk formatting** (`format-disk.sh`) rework with safer device selection and dialog flow
|
||||
- **Disk passthrough** for VMs and CTs — updated device enumeration, serial-based identification, and cleaner teardown
|
||||
- **NVMe controller addition for VMs** — improved controller type selection and slot detection
|
||||
- **Import disk image** — smoother path validation and progress reporting
|
||||
- **Disk & storage manual guide** refresh
|
||||
|
||||
### Hardware / GPU / TPU scripts
|
||||
- **Coral TPU installer** updated for current kernels and udev rules (Proxmox VE 8 & VE 9)
|
||||
- **NVIDIA installer** — cleaner driver installation, kernel header handling, and VM/LXC attachment flow
|
||||
- **GPU mode switch** (direct and interactive variants) — safer switching between iGPU modes
|
||||
- **Add GPU to VM / LXC** — unified selection dialogs and permission handling
|
||||
- **Intel / AMD GPU tools** kept in sync with the new shared patterns
|
||||
- **Hardware & graphics menu** restructured for consistency with the rest of ProxMenux
|
||||
|
||||
|
||||
## 2026-03-14
|
||||
|
||||
### New version v1.1.9 — *Helper Scripts Catalog Rebuilt*
|
||||
|
||||
Reference in New Issue
Block a user